


HOOK borrows (heavily at times) from other, more established data warehousing methodologies. The emphasis here is Data Warehouse, and as such, HOOK focuses on the four Inmon Criteria discussed in Chapter 1.
Subject-oriented
Integrated
Time-dependent
Non-volatile
Having a Data Lake at the heart of a HOOK implementation ticks off the time-variance and non-volatility criteria, but what about subject-oriented and integrated? These two criteria provide the organising mechanism for the data warehouse; it allows us to group related data assets in logical structures that enable us to locate them easily. For example, suppose I am looking for information about my customers; it should be easy for me to identify all the data assets in the Warehouse relating to that subject.
Organising Structure
To set the scene on how HOOK is different to the likes of Data Vault and Kimball, let me share with you an analogy that, I hope, will highlight the underlying principles of the organising capabilities of HOOK.
The Library Analogy
As far as I'm aware, libraries still exist. As a child, I was lucky enough to live a stone's throw away from our local community library, and I would spend many hours there hunting down books on science, computing and James Bond. I'm still not entirely sure why I had such a fascination with James Bond, but it's always cool to say to friends, “Yeah, the film was good, but it's nothing like the book."
We all like a good analogy, and it occurred to me that the HOOK approach to data warehousing mirrors how a library works. A library is just a big room that contains a whole bunch of shelves on which there are a whole bunch of books. The books happen to be organised or indexed so that it should be easy to locate books about a particular subject. Its organising structure is what makes a library work; otherwise, it is just a room full of books and finding what you want is an almost impossible task.
But the analogy doesn't stop there. When the library receives a new book, it is indexed based on the type of book and then placed in an appropriate location within the library alongside books of a similar kind. At no point is the book altered other than sticking an identifying label and barcode on it (tagged with metadata!); the book itself remains intact. We do not at any point go through the book, cutting it into pieces and filing each of those pieces individually. The book is immutable. I mention this because methodologies such as Data Vault and especially Kimball do precisely that. In those methodologies, the ingestion routines transform the source data by splitting or aggregating it before storing it permanently. Reconciling the data in the Warehouse back to originating source becomes problematic as it requires us to reconstitute the data into its original form. In some cases, this might not be possible1. With HOOK, the data in the Data Lake aligns directly with the source data. HOOK supports back-to-source reconciliation by default.
But we can improve upon the library paradigm. The problem with a library is that a book may only be categorised in one way. We can only store a book in a single location, which means that the index structures will be more complex than they need to be. For example, say there is a location in the library for books on science and another for biographies; where do I place James Gleick's excellent book “Genius2"? This book fits neatly into both categories, but we can only place it in one physical location. The reality is that there is a subcategory of the biographies section that contains biographies of scientists; it should be possible to find a single location in the library for this book. However, it now means that books relating to the broader category of science are not just contained in the science section of the library; there may be others scattered across many other subcategories.
What if it was possible to place the same book in multiple locations simultaneously? What if I could put my book in the biography section and the science section at the same time? In the physical world, this isn't possible unless we have multiple copies of the same book and plenty of room. Luckily in the digital world, cloning a data set without physically duplicating the data is as simple as setting up a new pointer. If I need ten different copies of the data, then set up ten pointers to it. How might this look if we did this for an actual library?
When a new book is received, it is tagged as before and then placed on a shelf (any shelf you like). We then make a note of exactly where that location is. Of course, this means that all the books are jumbled together in no particular order, but we have made a note of the location, say, Aisle 10 - Stack 5 - Shelf 4. We can tag the book with the location and information that indicates the categories the book belongs to. Assuming the index is electronic and can easily be searched, then when I search for books on science, I'll get a list of books and their locations3. If I want to read a book, I will need to physically walk to its location to retrieve it. Perhaps this is not efficient in retrieving all the books on the list as I may have to walk around most of the library. Again, the parallels to HOOK are uncanny. It is easy to get the book into the library and index it, but maybe not be as efficient at getting the book out to read it. However, the difficulty is not in reading the book, just in locating and fetching it in the first place. I will spend considerably more time reading the book than walking to retrieve it from the shelf.
To address the efficient retrieval problem, we still have options. Say, for example, I wanted to write a book on "Data Warehousing Methodologies" (crazy, I know). I might go to a library to do some research. I grab all the books I can find on the subject, pick out the bits I want, and then compile them into a whole new book. We can then store this new book in the library the same way as any other book. Then, when somebody comes into the library looking for information about data warehousing methodologies, we can direct them towards my new book (as well as others). As I've done all the heavy lifting summarising all the information from all those other books, I have saved that person from reading all those other books.
And so it is with HOOK. If the required data is too difficult to access because it is spread across different sources, why not create a new source that brings all that information together? That means transforming the data with some form of logic and ingesting the output as if it were just another source.
Categorising Data
Libraries have existed for centuries, so we can assume that the methods used to organise them are relatively mature. Most modern libraries use the Dewey Decimal Classification ("DDC"), which was first introduced in the late 19th century and has continued to evolve. The DDC defines a structured set of classifications that allow books and publications to be organised consistently, regardless of which library you visit.
At the top of the categorisation hierarchy, there are 10 broad categories:
000 – Computer science, information and general works
100 – Philosophy and Psychology
200 – Religion
300 – Social Sciences
400 – Language
500 – Pure Science
600 – Technology
700 – Arts and Recreation
800 – Literature
900 – History and Geography
Books in a library will be physically stored in locations that align with these categories; you would expect that all publications on Technology (600) would be found in the same part of the building. These broad categories are further subdivided into a classification hierarchy that decomposes into as many as one hundred thousand distinct categorisations, and each publication may only be assigned a single classification. In other words, we are only permitted to place a book in one location.
One hundred thousand may seem like a large number of categories, and you might expect that we can quickly identify one of them for each publication. However, this is not always the case. For example, where would we store a book on the history of technology? Do we record this under "600 - Technology" or "900 - History and geography"? Using a hierarchical classification, we have to "pick one" and then hope there is a sub-categorisation that allows us to cater for both. The reality is that sometimes we will end up with books in less than obvious places. If the book is filed under ‘600 - Technology', I'm never going to find it if I'm searching under '900 - History and Geography".
In the data warehouse, we are not limited by this physical constraint which means that we don't need to define a hierarchy but rather a set of broad categories with which we can tag our data assets. There is no reason why the same data asset cannot be tagged to belong to more than one category. This offers us an extremely flexible and simple way to categorise data. With only 10 categories, we can organise our data in any one of 2^10 (1024) different ways. With our ideal 150 categories, we have 2^150 (a ridiculously large number ~1.5 billion billion billion billion billion) permutations. We are free to allow our categories to overlap in any combination we like!
Unfortunately, we don't have a Dewey Decimal Classification for business, so we must create our own. This is where the business glossary comes into play. The terms or concepts defined in the business glossary are our classifications. Once we have a set of core business concepts, we can organise our data assets around them.
How we develop a useful set of Core Business Concepts and the relationships between them will be discussed in detail later in Section II (starting in Chapter 7) of this book.
These categories are equivalent to the subjects referred to in Inmon's subject-oriented criteria. Organising our data assets according to these categories meets this criterion.
Visualising Categorisations
They say a picture paints a thousand words, and as visual person I always findit useful to have a diagrammatic representation of concepts I’m trying to understand. Different visuals work better for some people than others, so in this section I’ll present a few examples that might help.
I’ll use an example of a hypothetical set of four source tables (see Figure 3.1) that tracks orders.
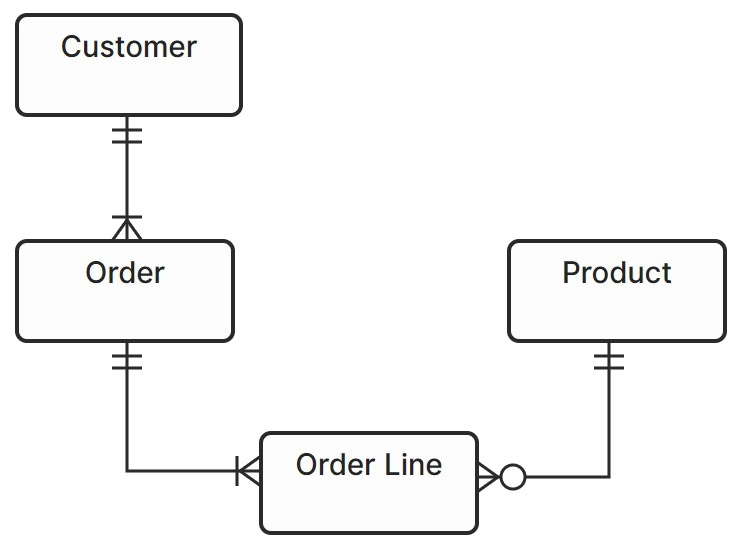
If you are unfamiliar with the modelling notation used in this example please refer to Appendix A for an overview.
Here we have four source tables which we plan to ingest into the data warehouse, and as such, we need to organise their data into categories. Assume that we already have a set of categories defined which include Customer, Order and Product. If we want to organise these four tables into these categories, how might that look?
Venn Diagram
We could visualise this as a Venn diagram, with the three categories represented as circles. We can then place each of the four tables on the diagram, ensuring we enclose each within the appropriate concept boundaries, as shown in Figure 3.2.
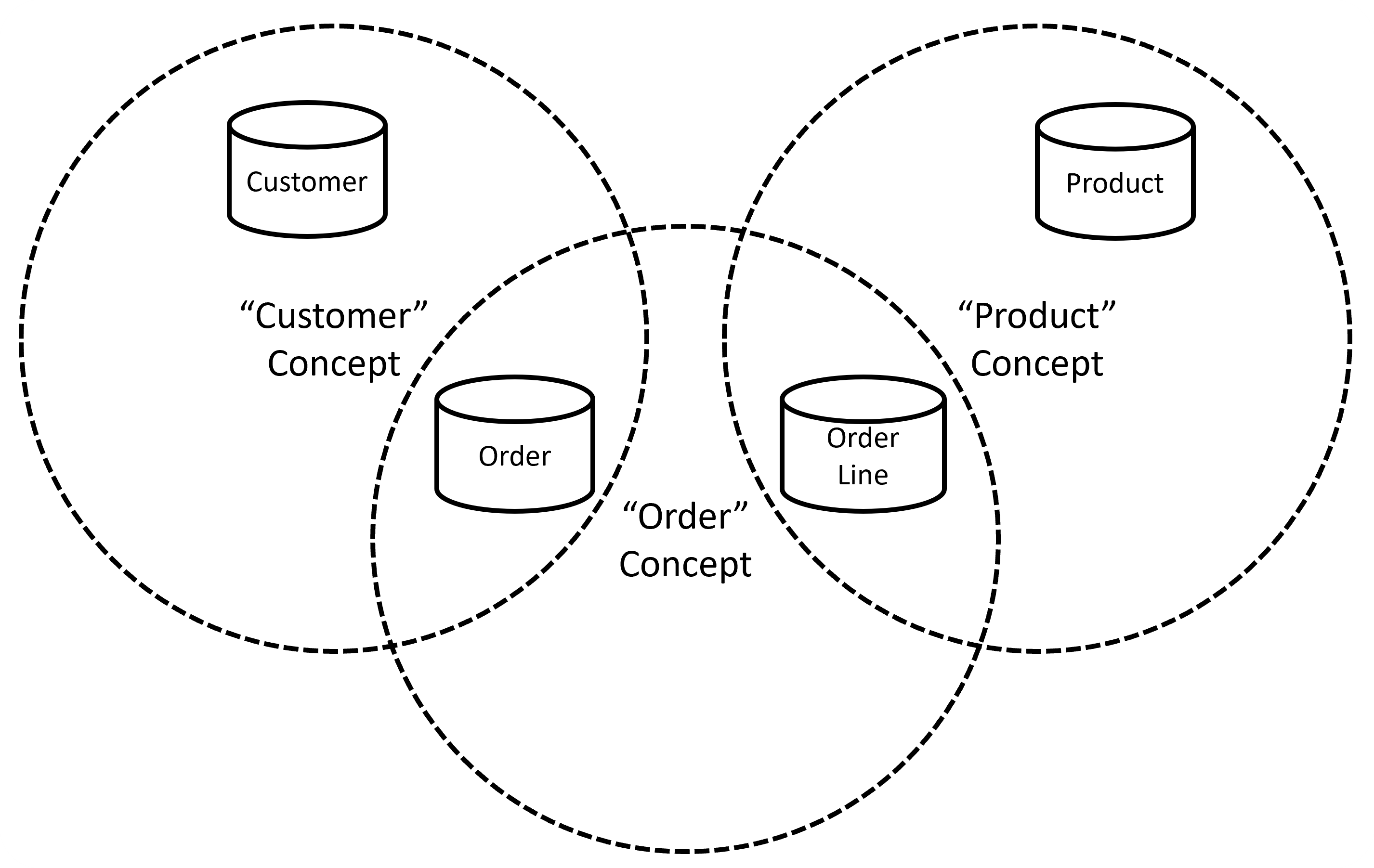
The Customer table is fully enclosed by the Customer concept, whereas both the Customer and Order concepts encompass the Order table.
BUS Matrix
Alternatively, we could construct a simple matrix, with the tables to be ingested listed on the left-hand side and then the business categories listed across the top.

Those familiar with Ralph Kimball's work will see similarities with the dimensional modelling BUS matrix. Here we can clearly see that the Order Lines are categorised by Order and Product, whereas the Orders table is categorised by Customer and Order.
The Hook Representation
I often use this type of visual when talking about HOOK, but it portrays the same meaning as the Venn diagram and BUS matrix form.

The diagram shows the source tables along the bottom that are suspended from one or more Hooks. Each Hook represents a business category.
The meaning in all three representations is exactly the same. However, if I was asked to pick one, I would recommend the BUS matrix form when formal documentation is required. This will certainly be easier to manage and offers a much clearer view of the overall categorisation structure, particularly as the number of categories (concepts) and source tables increase (consider what a Venn diagram would look like with 150 categories and thousands of source tables!)
Anatomy of a Business Concept
The business concept represents the categorisation subjects around which we want to organise the assets within the data warehouse. Therefore, it is imperative that each business concept is properly defined and documented before we attempt to align any data assets to them.
You are free to document them as you please, using any tools which are appropriate/available. Whatever method you do choose, make sure you are consistent in your level of documentation. This section outlines some suggestions on what you might consider capturing.
The example below shows the definition of a business concept called Product. You will see there are a number of sections to the definition, which are described in more detail below.

Name
Every business concept needs a name, and it must be unique. We should never have multiple business concepts with the same name (homographs). This might seem like an obvious statement, but within any organisation, it is surprisingly common for the same term to have different meanings. For example, the Sales and Human Resources departments might have very different views of what they mean by a client. The Sales department will regard people buying their products as clients. The HR department might see employees as their clients.
Each department has its own terminology. The language they use is specific to their operation and used in their day-to-day activities. For human beings to communicate efficiently, they need to use a common language. If we use entirely different languages, then communication is almost impossible. If we use a common language but use some words differently, then there is a high chance that communication will be inaccurate and misleading.
The simple solution is to impose a common language and set of definitions that we apply across the organisation. Unfortunately, different parts of the business are parochial (dare I say tribal) in nature and trying to enforce a standard language will usually be met with resistance. The best we can hope to achieve is to define a common language within the data warehouse itself. If anybody wants to use that data, then they will have no option but to use those definitions. Of course, we should try to align that language to that of the business, but there will be occasions where hard decisions have to be made, and we have to deviate to ensure clarity.
Keep the names as short as possible, preferably singular words and never use abbreviations. In certain circumstances, it would be acceptable to use acronyms but only if they are well understood within the business or if the name is not widely recognised in its full form4.
Definition
Creating good definitions is hard. Really hard. Even professionals who write definitions for a living often come up with less than satisfactory definitions.
Consider the definition of an Automobile. I copied this one from dictionary.com.
automobile [ aw-tuh-muh-beel ] (noun)
a passenger vehicle designed for operation on ordinary roads and typically having four wheels and a gasoline or diesel internal-combustion engine.
It seems like a pretty good definition, but as a layperson, even I can pick a few holes in this one. My perception of an automobile is a family car. The definition given above would also include vehicles such as buses. So is the definition wrong, or is my perception of what I think an automobile is? Either way, something isn’t quite right. Perception is the enemy here.
The definition also indicates that 'typically, an automobile has a gasoline or diesel internal combustion engine'. When this definition was written, this was perfectly adequate, but with the rise in popularity of electric-powered vehicles, this definition now looks a bit out of date. Our definitions, therefore, are not set in stone. As the world changes, business will evolve, and so too the language we use. We will need to periodically revisit the definitions of our business concepts to ensure they continue to be relevant.
There are a few guidelines we can use to help us pin down our concept definitions. When writing definitions, we should follow the 'three Cs5' in that our definitions should be clear, concise and correct.
Clear
It is difficult to define what I mean by clear, but as a general rule of thumb, a clear definition is one where you can read it just once and have a definite sense of what the concept means. If you find that you need to read and re-read the definition, then you have missed the mark. Of course, if you are the person writing the definitions, then you can't judge your own work, so take the time to test out the definition on other people.
Clear also means that the definition should be unambiguous. There should be no doubt in the reader's mind about what the definition means. Again, you can test this out by presenting the definition to different people to judge whether they have the same understanding. But you will need to be careful. Understanding is based on personal perception, and no two people will perceive the same thing the same way. Although we might think that different people have a common understanding, they might not.
Concise
The definition needs to be short and to the point. In general, one or two sentences should suffice. Nobody wants to read an essay, and if you find you need to write one, then you probably don't understand the concept yourself, or there are lower-level concepts at play which need to be teased out.
Correct
It may seem odd that I would call out that a definition should be correct. Of course, it should be correct. Why would anybody intentionally write an incorrect definition? The point here is that we should be able to test whether the definition is correct. Can we throw examples at the definition that contradicts the definition?
I remember discussing this very point with my wife when I explained how difficult it is to come up with good definitions. As an example, I asked her to give me the definition of a helicopter. She said something like:
helicopter [hel-i-kop-ter] (noun)
An airborne mode of transport.
Does our notion of a helicopter fit this definition? Is a helicopter an airborne mode of transport? Yes, it is. But is the definition correct? I can think of other examples that also fit the definition. What about an aeroplane, a hot-air balloon or a hang-glider? Our concept of a helicopter certainly fits the definition, but if we can think of examples that also fit the definition but are clearly not helicopters, then the definition falls short.
If we fail to think of any counterexamples, then there is a high probability that the definition is correct. Dictionary.com gives this definition.
helicopter [hel-i-kop-ter] (noun)
any of a class of heavier-than-air craft that are lifted and sustained in the air horizontally by rotating wings or blades turning on vertical axes through power supplied by an engine.
It is far more difficult to think up examples that are not helicopters that fit this particular definition. By this definition, is a drone a helicopter?
As I said, writing good definitions is really hard but worth the effort to get them right. Even if you have no intention of building a data warehouse, having a solid set of business concept definitions will benefit the organisation by promoting a common understanding of the business.
Type
A business concept will be one of three types.
Core
Non-core
Deprecated
What makes a concept a core concept? Another difficult question to answer, but if you spend any amount of time talking with the people within the business, you will begin to recognise them intuitively. You will quickly realise that there are hundreds, even thousands, of business concepts at play within your organisation, but only a small subset of those concepts is needed to express the essence of the overall business.
These Core Business Concepts are important for the organisation. They can be uniquely identified and have clear definitions and context to describe them. You'll know they are important as they will be the terms and language used by the staff across the organisation in the day-to-day operation of the business. The following are good examples of Core Business Concepts: Customer, Employee, Asset, Account, Product, Order.
These are "big-ticket items". The following are also business concepts but, perhaps, do not qualify as Core Business Concepts: Order Line, Customer Type, Postcode.
A deprecated Concept is no longer in use within the business, but rather than removing it from the glossary, we can simply mark it as deprecated. You never know when you might need it again.
Just by looking at the list of core business concepts, it will be possible to figure out the type of business the organisation is engaged in. No two companies will have the same list, but similar businesses will have similar lists.
This opens up the possibility of creating pre-defined industry standard sets of terms that can be re-used, thus allowing data warehouse development to be fast-tracked.
Examples
Often, defining a completely robust definition will be too difficult to achieve. This is generally the case when different people have different perceptions of what a concept means. One way to influence perception is to present a set of real-life examples of the business concept. For example, if a bus is listed as an example of an automobile, then my perception will be immediately altered, or at the very least, it might prompt me to seek clarification from the Data Steward.
Try to list as many examples as possible (within reason) and check that each of them fits the definition. Otherwise, the definition might be incorrect, and we need to clarify it. Alternatively, we might realise that there is a different business concept at play which we have yet to identify.
You might also consider listing counter-examples. These are examples which are explicitly excluded from the concept even though they might, at a first glance, seem to fit. Again listing counter-examples can help to change our perception of the concept being defined. Revisiting our earlier example, we might explicitly call out that drones are not helicopters.
Business Rules (Ontology)
What is an ontology, and what does it have to do with data warehouses? This is the definition from Google:
ontology [ on-tol-uh-jee ] (noun)
(1) the branch of metaphysics dealing with the nature of being.
(2) a set of concepts and categories in a subject area or domain that shows their properties and the relations between them.
The first definition is in the realm of philosophy, so I'll avoid that one. The second definition is closer to something we can use:
An ontology is a set of concepts that shows their properties and the relations between them.
This sounds an awful lot like a data model to me. If I replace certain words, the definitions are almost identical.
A data model is a set of entities that shows their attributes and the relationships between them.
A data model is a very useful tool to help communicate how a business is structured. By understanding the concepts that are at play and the way they relate to one another, we can form a clear mental view (perception) of how the business operates. I like to think of a data model as a framework/skeleton/foundation upon which business processes may be built. Business processes represent the machinery of the organisation, the activities that get things done. The data model, or more precisely, the data that it represents, can be thought of as the fuel that drives that machinery.
Strictly speaking, we only need a set of business concepts to deliver our data warehouse (remember the Inmon Criteria). A full-blown enterprise data model is very much a nice-to-have, but if you are serious about gaining a proper understanding of how your organisation functions, it is well worth the effort. Having an enterprise data model in place will certainly help improve your understanding, and therefore the quality, of your data. Mandatory? No. Recommended? Certainly.
Taxonomy
Taxonomies are, perhaps, something that we as human beings are more familiar with, even if we don't use the word in day-to-day conversation. Here is a definition.
taxonomy [ tak-son-uh-mee ] (noun)
(1) the science or technique of classification.
(2) a classification into ordered categories: a proposed taxonomy of educational objectives.
(3) Biology. the science dealing with the description, identification, naming, and classification of organisms.
Classification is the important word here. There are entire branches of science dedicated to classifying things. Biology, as one of the definitions suggests, is a classic example. Living organisms can be grouped into broad categories, such as plants, fungi, and animals. Then each of those categories can be further subdivided6. Animals might be broken down into vertebrates, invertebrates, and so on.
The point is that we, as human beings, are comfortable organising things into categories, and so it is with the concepts we use within the business. For example, we might talk in general terms about products, even though there are many different types of products.
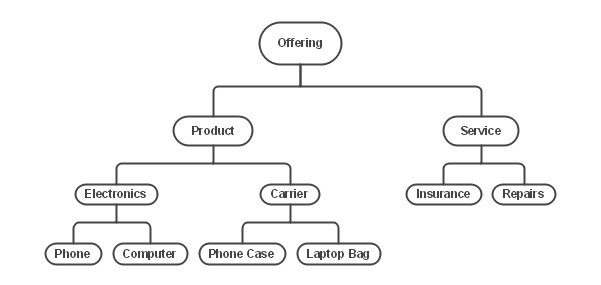
Figure 3.5 shows a simple taxonomy hierarchy for products and services. At the top of the diagram, we have the general Offering concept. Below the Offering concept, there are two sub-concepts, more commonly referred to in data modelling speak as sub-types, in this case, Product and Service. Each of these sub-types will have its own definition, but it must be consistent with its parent. In other words, the definitions of Product and Service must not contradict the definition of Offering.
Synonyms
Although the goal is to define a set of Core Business Concepts that are recognised globally across the organisation, the reality is that local language will generally prevail. Each department within an organisation will have its own vocabulary that won't always align with enterprise terminology. This is particularly common when different organisations are brought together during an acquisition.
Later in this book, we introduce two fictional organisations, Widget World and Stationery Station, who use the terms Widget and Offering, respectively, to describe the products they sell. When we bring these organisations together, we can either ask them to forego their local terms in favour of the enterprise term of Product; or allow them to continue with their own local vocabulary and record synonyms that map the local terms to the enterprise term. Hint: the latter approach is the only one that ever works.
There may be multiple alternative terms used within the business locally that refer to the same enterprise concept, and they should be listed along with an indication of the local vocabulary where it is used.
Data Steward
It is often the case that the responsibility of building and maintaining the Business Glossary and Enterprise Conceptual/Data Model falls to the IT department. The reason for this is that the IT department needs these resources to help them implement the systems required to support the business. The business, because they are the business, understands the concepts at play in their areas of responsibility; they don't necessarily need to write them down; they just know them.
If the business understands these concepts, then it should be its responsibility to write down the definitions (to help IT, to help them). Therefore, every term should be assigned a Data Steward, the person, department or team that best understands the concept and is best equipped to write down its definition.
Last Revised
We cannot set and forget any of the concept definitions. The world does not stand still, and concepts and their definitions can, and most likely will, change over time. It is recommended that the date the definition was last reviewed and revised be recorded for every concept in the glossary. Every definition should be revisited regularly.
A thorough treatment of definitions is beyond the scope of this book, but you may find the book by Ronald G. Ross “Business Knowledge Blueprints: Enabling your data to speak the language of the business” (1st edition, ISBN 987-0-941049-17-7), of interest.
The Magic of 150
The business glossary is a list of business terms or concepts that are synonymous with the categories we have been discussing. As I have already suggested, we need to keep the number of Core Business Concepts to a manageable number, which should be around the 150 mark. But what is so special about this number?
Dunbar’s Number
In the 1990s, a British anthropologist named Robin Dunbar was conducting a study trying to establish a correlation between the brain size of primates and the number of members in their social groups. From his research, he concluded that the average size of a social group in human society is around 150 people. In other words, a typical human being is only able to maintain meaningful relationships with around 150 other people. It is the group of people with whom they are familiar and comfortable. This number is known as Dunbar's Number.
It occurred to me that the number of common Core Business Concepts within an organisation might also mirror this number. You can think of these business concepts as members of the organisational social circle. If the human brain can maintain around 150 relationships, it makes sense that a typical employee has the capacity to comprehend 150 business concepts.
If we want to share a common understanding of the entire business across all business employees, we should aim to limit the number of business concepts to around 150. If we have a shared understanding of these concepts, then the communication between employees will be more consistent and accurate.
Levelling within Taxonomies
It can be difficult to limit the number of Core Business Concepts to a mere 150. In a workshop environment, it would be very easy to gather dozens of terms in a short space of time, focusing on just one small part of the business. It would be all too easy for the number of terms to blow out to hundreds or even thousands. But not all these terms will be Core Business Concepts, and you will find that many of the terms are more specific examples of more general terms.
For example, in Figure 3.4, the Offering taxonomy shows eleven different terms. Should we consider all of them as Core Business Concepts? Of course not. We don’t need to get down into the details to have an understanding of what the business is dealing with. Equally, we need a suitable level of granularity; otherwise, our terms will be too generic and meaningless.
We need to make judgement calls about where the sweet spot should sit. We can do this by starting with the most generic term and asking whether the term is used frequently by the business. If you record a transcript of your conversations with the business, it will become apparent which terms are talked about more often.
Let’s try this with the Offering taxonomy. We start at the top with the most general term of Offering. Does the business talk about Offerings? Probably not; it is a very generic term that, on its own, doesn’t hold much meaning. We move down to the next level down and repeat the process.
At the next level down, we have Products and Services. These terms are definitely talked about more within the business, so these look like promising candidates for Core Business Concept. But just to be sure, we drill down a little deeper. Within Product, we have Electronics and Carriers. These terms are starting to feel a bit too detailed. I don’t need to know specifically about Electronic products when discussing sales or shipping; I can use the term Product happily with no loss of meaning when talking about these processes.
Drilling down into Service, we have Insurance and Repairs. Unlike the detail under Products, these terms do seem to have very specific meanings with regard to processes within the business. Insurance and Repairs are two very different terms that require very different processes to handle them, so they are also good Core Business Concept candidates.
Based on this analysis, we have chosen four of the eleven terms as Core Business Concepts, as shown in Figure 3.6, and we have a better chance of keeping the number of Core Business Concepts under the 150 mark.
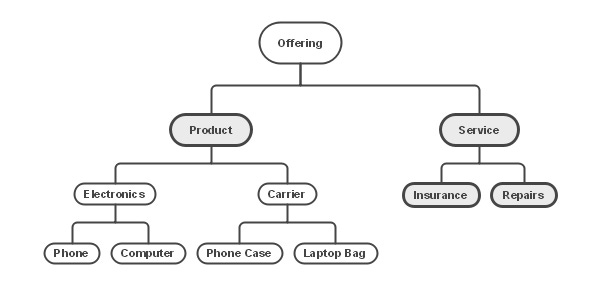
You might ask whether we need Service in addition to Insurance and Repairs. After all, Insurance and Repairs cover all Services, so aren’t we repeating ourselves if we use all these terms? Yes, we could certainly have made that decision, but the problem we have is that the choice of which terms are and are not to be treated as Core Business Concepts seems a little arbitrary.
There's a better way. In Chapter 7, I will introduce Ensemble Logical Modelling (ELM), a data modelling technique that allows us to zero in on a coherent set of Core Business Concepts in a business-focused, systematic and repeatable way.
Summary
Core Business Concepts and the Business Glossary form the foundation of a HOOK Warehouse. Organising the Warehouse data around a solid set of well-defined business terms improves the utility of the data, elevating what would be a data swamp into a highly structured set of data assets.
As we will see in the following chapters, Core Business Concepts can be equated to a Hook in the HOOK methodology. But we will also see how Hooks can be formed, allowing us to form Natural Business Relationships between Core Business Concepts.
Next Chapter
In Chapter 4, we will dig into the Hook construct.
Many thanks to the kind folk at Ellie for granting me access to their cloud-based business glossary and data modelling tool, which I’ve used to produce the diagrams in this article.
Being able to reconcile the data in the data warehouse back to source data is a fundamental test case. If it cannot be done then the data warehouse is not fit for purpose.
Gleick, James (1992). “Genius : Richard Feynman and Modern Physics” (ISBN 0-349-10532-4), which documents the extraordinarily colourful life of physicist Richard Feynman. Highly recommended.
Isn’t this how a Google search works? Key in some search criteria and get a list of links. Google doesn’t store the data at the ends of those links, but it does know how to direct you there.
I worked on a project where the business used a Health and Safety term called a SLAM, an acronym for Stop-Look-Assess-Manage. SLAM is a recognised concept within the business but never referred to in its expanded form.
The three C's is inspired by the three C's (Clarity, Completeness and Correctness) from The Rosedata Stone.
Hoberman, Steve (2020). “The Rosedata Stone : Achieving a Common Business Language using the Business Terms Model” (1st edition, ISBN 978-1-634627-73-3)
Apologies for the simplicity of the example. The biological taxonomy is far more sophisticated than I have described here consisting of eight hierarchical levels:
Domain ← Kingdom ← Phylum ← Class ← Order ← Family ← Genus ← Species